
About Me
I’m currently a 3rd-year Ph.D. candidate in the Department of Automation at  Tsinghua University. Prior to this, I earned my B.Eng. degree from the School of Automation Science and Engineering,
Tsinghua University. Prior to this, I earned my B.Eng. degree from the School of Automation Science and Engineering,  Xi’an Jiaotong University in 2023. I worked closely with Shuai Zhang and Zhengqi Wen. I am fortunate to collaborate with Zheng Lian, Haoran Luo, Zhengxi Lu, Yuhao Shen, and Fan Zhang.
Xi’an Jiaotong University in 2023. I worked closely with Shuai Zhang and Zhengqi Wen. I am fortunate to collaborate with Zheng Lian, Haoran Luo, Zhengxi Lu, Yuhao Shen, and Fan Zhang.
My research interests focus on LLM / MLLM reasoning, planning, and agentic reinforcement learning. From 2024 to early 2025, my work mainly focus on high-quality and efficient reasoning for LLMs. My current research investigates post-training techniques for general agents, including agent skills, on-policy distillation (OPD), and reinforcement learning (RL).
🐈 Collaboration: I am looking for motivated collaborators interested in the above topics. If you would like to explore these directions together, feel free to contact me. UG/MSc students are also welcomed! 🌱
🔥 News
- 2026.07🎉 Selected for the CIE-Tencent Doctoral Research Incentive Project (44 recipients nationwide, ¥100,000 Grant)!
- 2026.07🚀 Released SEED, a self-evolving on-policy distillation framework for agentic RL, featured as 🤗 HF Daily Paper #3!
- 2026.07🏆 Double received the SAC Highlight Award at ACL 2026 (~50/12,148), selected as the best outstanding paper in the SAC batch!
- 2026.07🪑 Serving as Virtual Session Chair (Language Model) at ACL 2026.
- 2026.06🚀 Released OPID, TACO, Orchestra-o1. OPID featured as 🤗 HF Daily Paper #3!
- 2026.05🎙️ Presented Maestro at AliStar Academic Open Day, Beijing 🇨🇳.
- 2026.05🚀 Released Maestro, RobotEQ, SDAR, AffectGPT-RL. SDAR featured as 🤗 HF Daily Paper #2!
- 2026.05✈️🏛️ Attending VALSE 2026 at Wuhan 🇨🇳
- 2026.04🚀 Released SKILL0 on skill internalization, featured as 🤗 HF Daily Paper #2!
- 2026.04🎉 Six papers accepted to ACL 2026, including one oral and best paper candidate (Double). See you in San Diego 🇺🇸!
- 2026.02🎉 Two papers accepted to ICLR 2026!
- 2026.01✈️ Attended AAAI 2026 in Singapore 🇸🇬
- 2025.12🎤 Attended the 2025 China Metaverse Conference in Wenzhou 🇨🇳.
- 2025.11🎉 Two papers accepted to AAAI 2026 (one oral presentation)!
- 2025.11✈️📍 Attending EMNLP 2025 in Suzhou 🇨🇳
- 2025.05🎉 NoiserBench accepted to ACL 2025!
📝 Selected Publication(Full List)
* Equal contribution. † Corresponding author.
🤖 Agentic Post Training
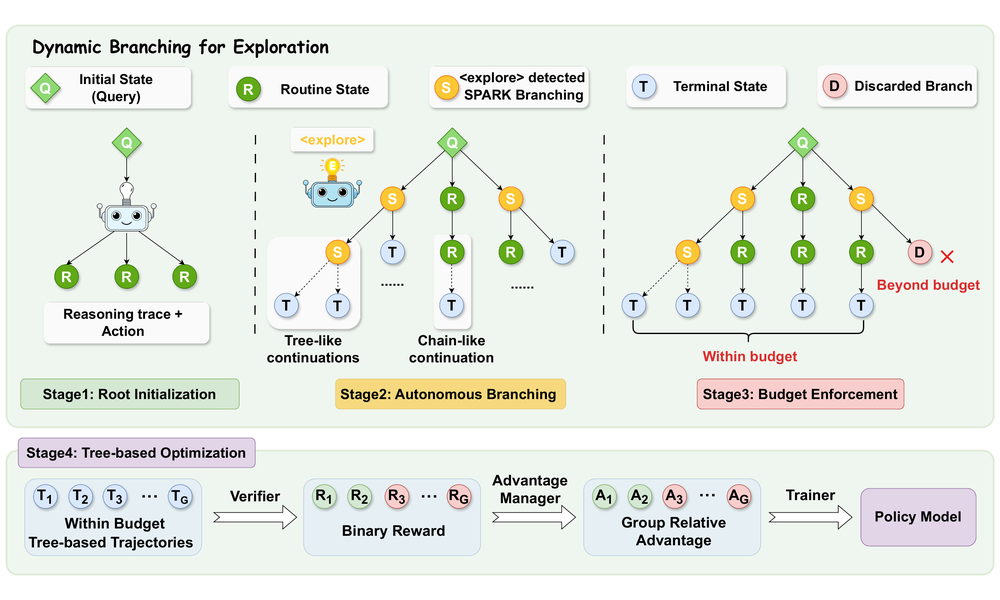
SPARK: Strategic Policy-Aware Exploration via Dynamic Branching for Long-Horizon Agentic Learning
Jinyang Wu, Shuo Yang, Changpeng Yang, Yuhao Shen, Shuai Zhang, Zhengqi Wen, Jianhua Tao
- We propose a policy-aware branching framework that allocates exploration budget to critical decision states, improving sample efficiency for long-horizon agentic RL.
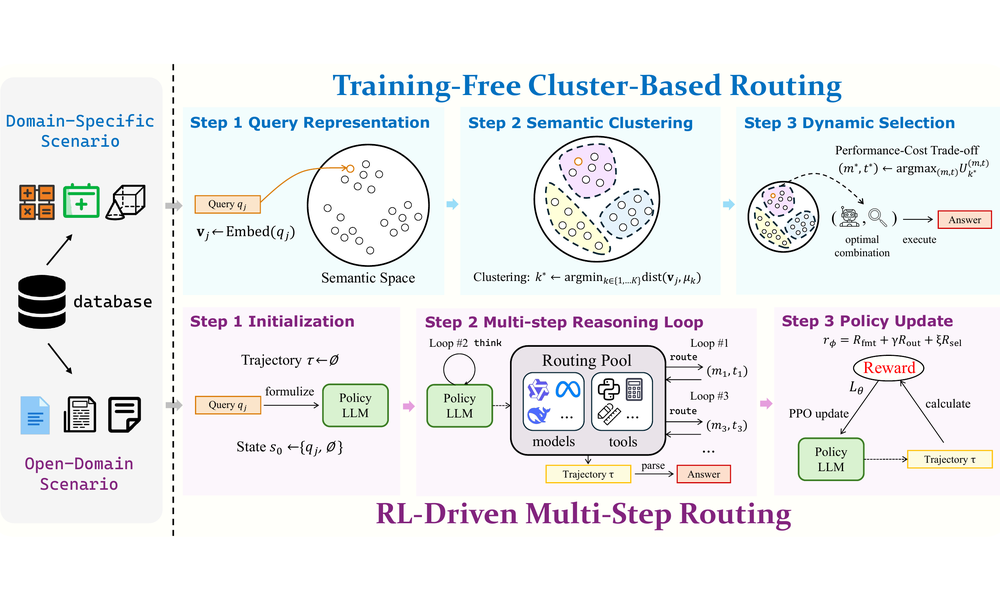
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning
Jinyang Wu, Guocheng Zhai, Ruihan Jin, Jiahao Yuan, Yuhao Shen, Shuai Zhang, Zhengqi Wen, Jianhua Tao
- We introduce a dual-path framework for dynamic tool usage, combining cluster-based routing with RL-based multi-step routing for cross-domain reasoning.
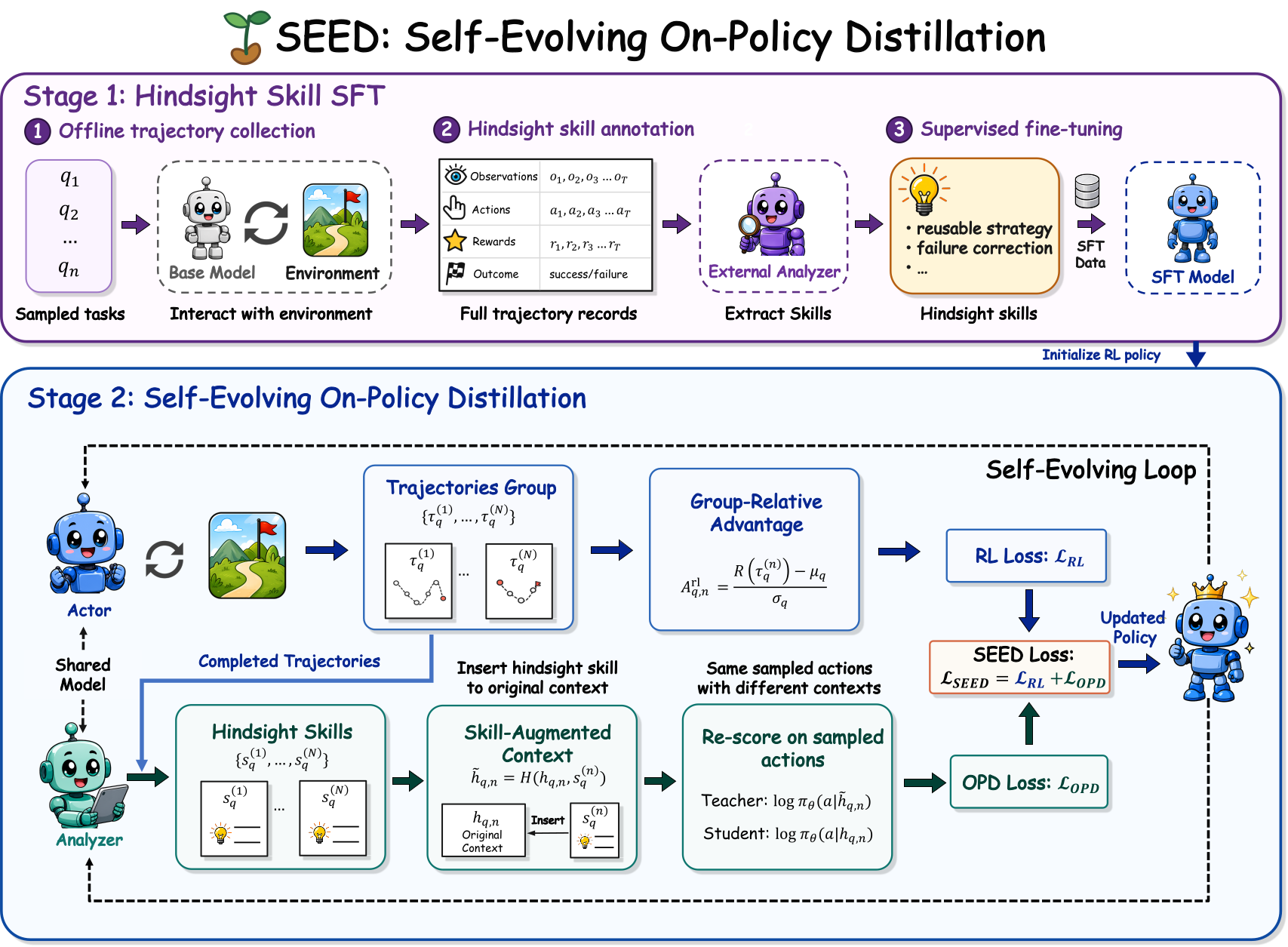
SEED: Self-Evolving On-Policy Distillation for Agentic Reinforcement Learning
Jinyang Wu*, Shuo Yang*, Zhengxi Lu, Fan Zhang, Yuhao Shen, Lang Feng, Haoran Luo, Zheng Lian, Shuai Zhang, Zhengqi Wen, Jianhua Tao
- We turn completed on-policy trajectories into evolving hindsight skills and dense token-level supervision for long-horizon agentic reinforcement learning.
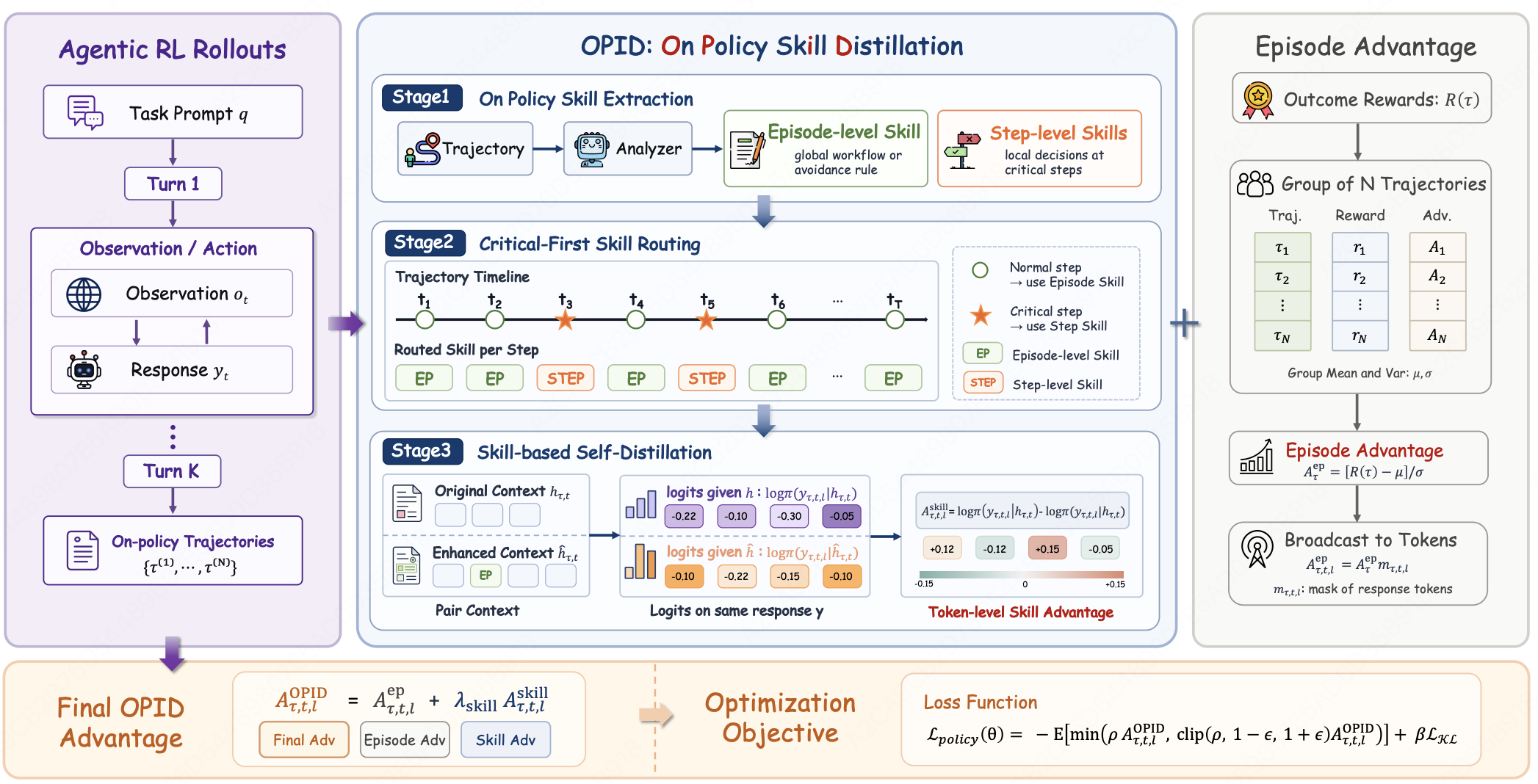
OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
Shuo Yang*, Jinyang Wu*,†, Zhengxi Lu, Yuhao Shen, Fan Zhang, Lang Feng, Shuai Zhang, Haoran Luo, Zheng Lian, Zhengqi Wen, Jianhua Tao
- We extract hierarchical skill supervision from completed on-policy trajectories and convert hindsight skill signals into dense token-level advantages for agent training.
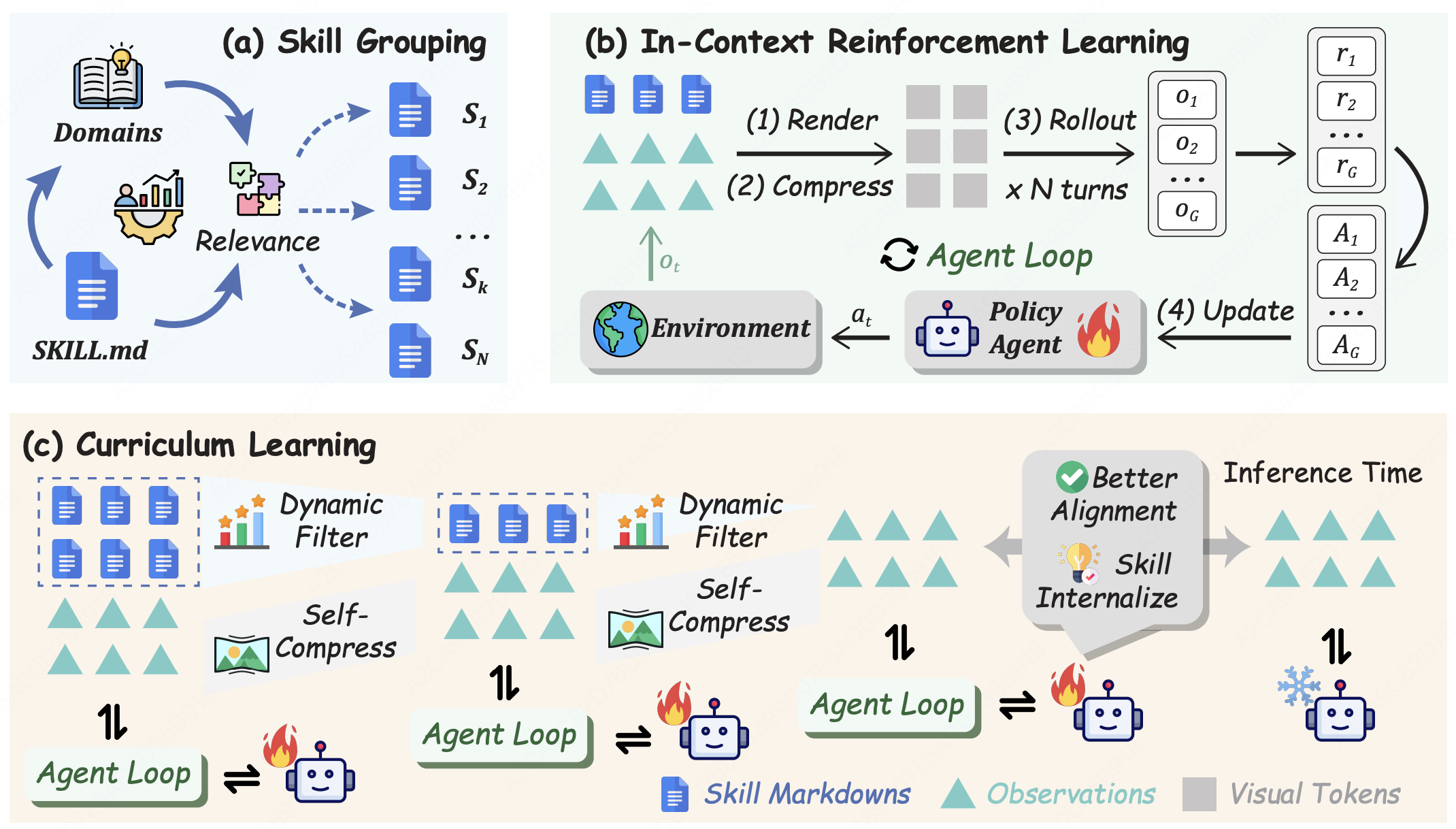
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
- We study skill internalization for agents, gradually withdrawing runtime skill context so the policy can acquire reusable behaviors into its parameters.
- Preprint Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles, Jinyang Wu, Guocheng Zhai, Ruihan Jin, Yuhao Shen, Zhengxi Lu, Fan Zhang, Haoran Luo, Zheng Lian, Zhengqi Wen, Jianhua Tao
 HF Code BIB
HF Code BIB - Preprint TACO: Tool-Augmented Credit Optimization for Agentic Tool Use, Mingkuan Feng*, Jinyang Wu*,†, Hao Gu, Fangrui Lv, Ruihan Jin, Chuyuan Zhang, Zhengqi Wen, Jianhua Tao HF BIB
- Preprint SDAR: Self-Distilled Agentic Reinforcement Learning, Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen HF Code BIB
- Preprint OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions, Fangzhi Xu, Hang Yan, Qiushi Sun, Jinyang Wu, Zixian Huang, Muye Huang, Jingyang Gong, Zichen Ding, Kanzhi Cheng, Yian Wang, Xinyu Che, Zeyi Sun, Jian Zhang, Zhangyue Yin, Haoran Luo, Xuanjing Huang, Ben Kao, Jun Liu, Qika Lin HF Code BIB
- Preprint Orchestra-o1: Omnimodal Agent Orchestration, Fan Zhang, Vireo Zhang, Shengju Qian, Haoxuan Li, Hao Wu, Jinyang Wu, Donghao Zhou, Zhihong Zhu, Zheng Lian, Xin Wang, Pheng-Ann Heng HF Code BIB
- Preprint RobotEQ: Transitioning from Passive Intelligence to Active Intelligence in Embodied AI, Kuofei Fang, Xinyi Che, Haomin Ouyang, Shufan Zhang, Xuehao Wang, Qi Liu, Liyi Liu, Chenqi Zhang, Wenxi Cai, Wenyu Dai, Jinyang Wu, Fan Zhang, Haoyu Chen, Bin He, Zheng Lian HF BIB
🧠 LLM Reasoning
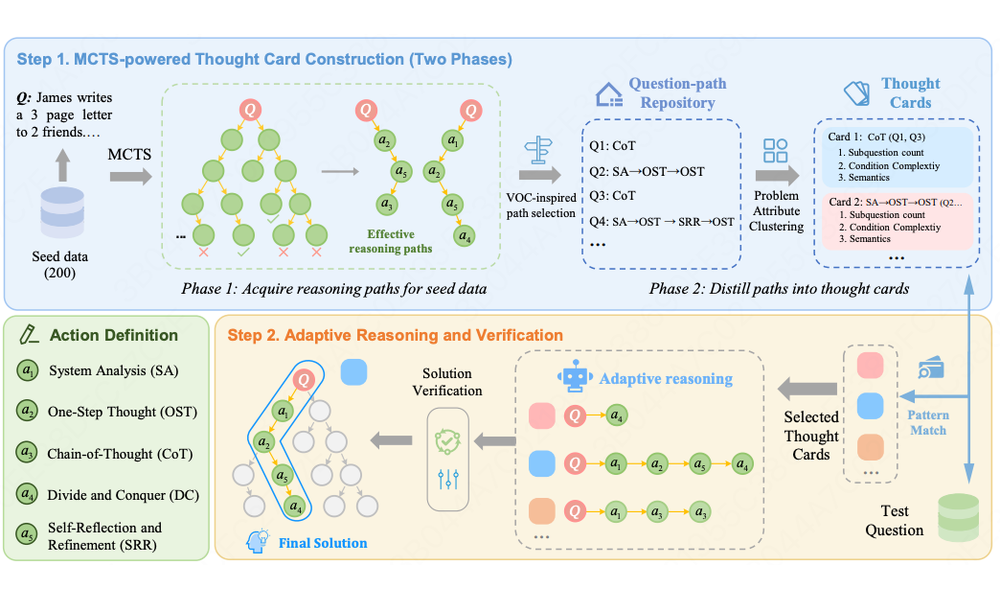
Beyond Examples: Towards Automated Thought-level In-Context Reasoning for Large Language Models
Jinyang Wu, Mingkuan Feng, Shuai Zhang, Feihu Che, Zhengqi Wen, Chonghua Liao, Ling Yang, Haoran Luo, Zheng Lian, Jianhua Tao
- We shift in-context reasoning from example-level imitation to reusable thought patterns, enabling automated and efficient reasoning guidance.
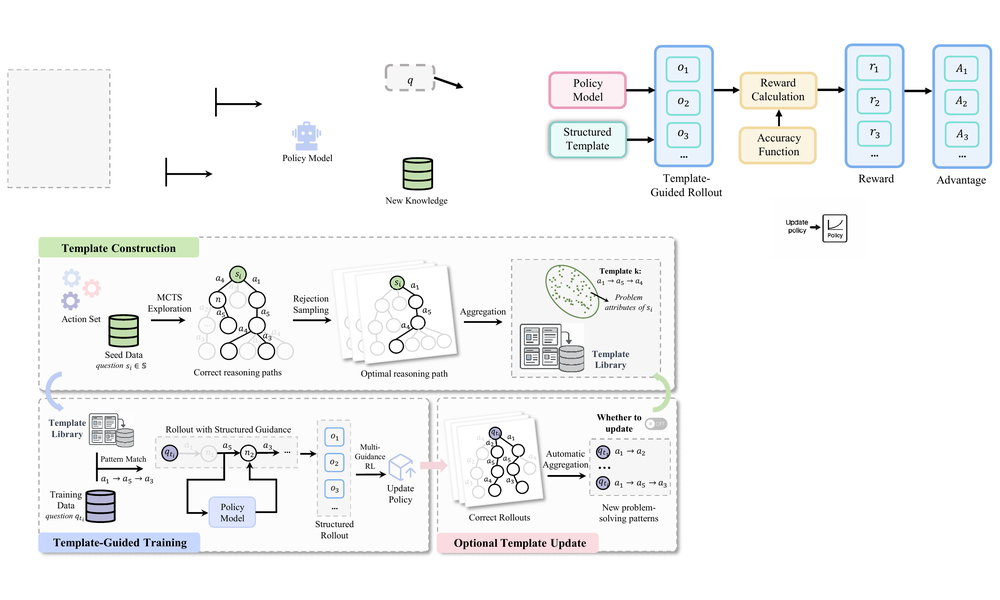
TemplateRL: Structured Template-Guided Reinforcement Learning for LLM Reasoning
Jinyang Wu, Chonghua Liao, Mingkuan Feng, Shuai Zhang, Zhengqi Wen, Haoran Luo, Ling Yang, Huazhe Xu, Jianhua Tao
- We augment policy optimization with structured templates, improving high-quality rollout generation and stabilizing RL training for reasoning.
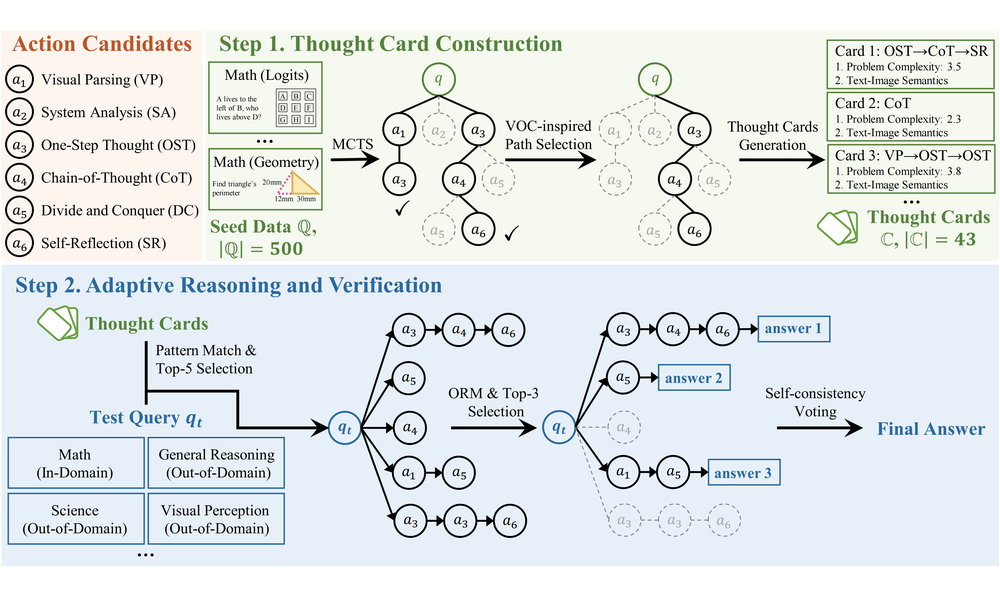
AStar: Boosting Multimodal Reasoning with Automated Structured Thinking
Jinyang Wu, Mingkuan Feng, Guocheng Zhai, Shuai Zhang, Zheng Lian, Fangrui Lv, Pengpeng Shao, Ruihan Jin, Zhengqi Wen, Jianhua Tao
- We build a training-free structured thinking method for multimodal reasoning, retrieving reusable thought cards at test time to guide MLLMs.
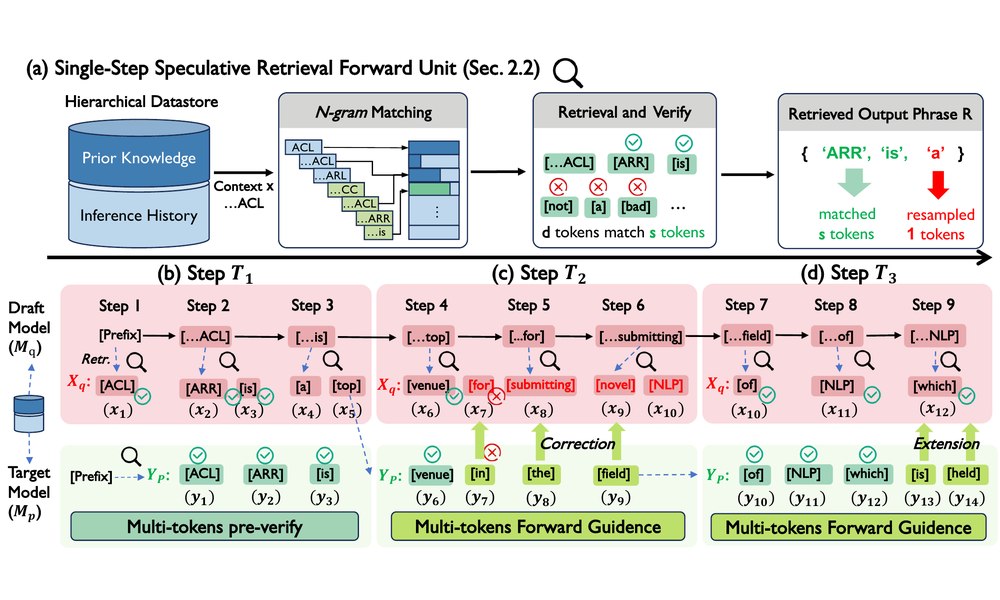
Double: Breaking the Acceleration Limit via Double Retrieval Speculative Parallelism
Yuhao Shen, Tianyu Liu, Junyi Shen, Jinyang Wu, Quan Kong, Li Huan, Cong Wang
Paper ![]() HF – Code BIB
ACL 2026 Best Paper Candidate (SAC Highlight/Oral)
HF – Code BIB
ACL 2026 Best Paper Candidate (SAC Highlight/Oral)
- We bridge speculative decoding and retrieval-based guidance to push inference acceleration beyond conventional parallel speculative decoding limits.
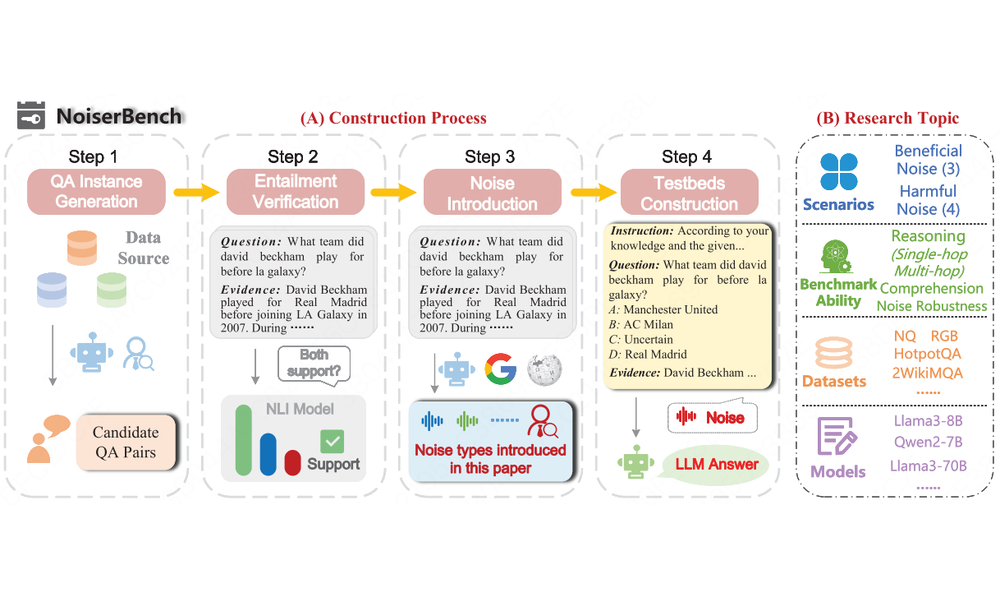
Jinyang Wu, Shuai Zhang, Feihu Che, Mingkuan Feng, Pengpeng Shao, Jianhua Tao
- We define a linguistic taxonomy of RAG noise and build NoiserBench to study when retrieval noise harms or surprisingly helps LLM reasoning.
- ACL 2026 Two-Stage Regularization-Based Structured Pruning for LLMs, Mingkuan Feng*, Jinyang Wu*, Siyuan Liu, Shuai Zhang, Ruihan Jin, Feihu Che, Pengpeng Shao, Zhengqi Wen, Jianhua Tao Code BIB
- AAAI 2026 From Imitation to Discrimination: Toward A Generalized Curriculum Advantage Mechanism Enhancing Cross-Domain Reasoning Tasks, Changpeng Yang*, Jinyang Wu*, Yuchen Liu, Shuai Zhang, Yang Li, Qiliang Liang, Hongzhen Wang, Shuai Nie, Jiaming Xu, Runyu Shi, Ying Huang, Guoquan Zhang HF BIB
- ICLR 2026 Exploring Knowledge Purification in Multi-Teacher Knowledge Distillation for LLMs, Ruihan Jin, Pengpeng Shao, Zhengqi Wen, Jinyang Wu†, Mingkuan Feng, Shuo Yang, Chu Yuan Zhang, Jianhua Tao BIB
- ICLR 2026 Attend to the Active: Structure-Aware Dynamic Attention in LLMs for Compositional Instruction Following, Fangrui Lv, Yulei Qin, Ruixin Hong, Liang Jian, Jinyang Wu, Ke Li, Xing Sun, Changshui Zhang BIB
- EMNLP 2025 RadialRouter: Structured Representation for Efficient and Robust Large Language Models Routing, Ruihan Jin, Pengpeng Shao, Zhengqi Wen, Jinyang Wu, Mingkuan Feng, Shuai Zhang, Jianhua Tao BIB
- Preprint DReSS: Data-driven Regularized Structured Streamlining for Large Language Models, Mingkuan Feng, Jinyang Wu, Shuai Zhang, Pengpeng Shao, Ruihan Jin, Zhengqi Wen, Jianhua Tao, Feihu Che BIB
- Preprint AffectGPT-RL: Revealing Roles of Reinforcement Learning in Open-Vocabulary Emotion Recognition, Zheng Lian, Fan Zhang, Lan Chen, Yazhou Zhang, Rui Liu, Jinyang Wu, Haoyu Chen, Xiaobai Li, Xiaojiang Peng, Bin He, Jianhua Tao BIB
🧬 Biomedical AI
- Briefings in Bioinformatics 2023 KGETCDA: An Efficient Representation Learning Framework Based on Knowledge Graph Encoder from Transformer for Predicting circRNA-Disease Associations, Jinyang Wu, Zhiwei Ning, Yidong Ding, Ying Wang, Qinke Peng, Laiyi Fu
- IEEE JBHI 2023 BertNDA: A Model Based on Graph-BERT and Multi-Scale Information Fusion for ncRNA-Disease Association Prediction, Zhiwei Ning, Jinyang Wu, Yidong Ding, Ying Wang, Qinke Peng, Laiyi Fu
👨🏫 Teaching
- Teaching Assistant, Affective Computing, graduate course.
- Teaching Assistant, Intelligent Speech Processing, undergraduate interdisciplinary innovation training course.
🎖 Honors and Awards
- 2026: CIE-Tencent Doctoral Research Incentive Project (中国电子学会-腾讯博士生科研激励计划, 44 Recipients Nationwide, ¥100,000 Grant).
- 2026: Outstanding Student Cadre, Tsinghua University.
- 2026: Merit Student, Tsinghua University.
- 2025: Outstanding Teaching Assistant, Tsinghua University.
- 2025: First-Class Scholarship of Tsinghua University.
- 2024: Second-Class Scholarship of Tsinghua University.
- 2023: Outstanding Graduate, Shaanxi Province.
- 2023: Outstanding Graduate, Xi’an Jiaotong University.
- 2022: First Prize, Chinese Mathematics Competitions.
- 2021: National Scholarship, Ministry of Education of China.
📖 Educations
- 2023.09 - now: Ph.D. student in Pattern Recognition and Machine Learning, Tsinghua University.
- 2019.09 - 2023.06: B.Eng. in Automation, Xi’an Jiaotong University.
🧑⚖️ Academic Services
Journal Reviewer
- Expert Systems With Applications (ESWA).
- ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM).
Conference Reviewer
- Top-tier ML/AI Conferences: NeurIPS (2025–2026), ICML (2026), ICLR (2026), AAAI (2026–2027).
- Top-tier CV Conferences: CVPR (2026), ECCV (2026).
- Top-tier NLP Conferences: ACL ARR (2026).
💬 Invited Talks
- 2025.12: I gave an invited talk on memory usage, hosted by the Metaverse Technical Committee of the Chinese Association for Artificial Intelligence.
- 2025.05: I gave an invited talk on in-context reasoning at the 7th Beijing Universities Artificial Intelligence Academic Forum.